
 Verena
Verena Muon (Jordan Keller, 2024) is a promising optimizer for LLM pretraining, but it is not fully plug-and-play at smaller scale. This post covers what it takes to get it working well at 280M parameters, and why splitting fused projections is the key.
Muon is an optimizer for Linear layers that differs from AdamW by optimizing not just the weight update magnitude, but also the direction. Because it uses the weight matrix itself to determine the update, having the weights fused (where two different layers are initialized as one for kernel efficiency) plays a role in how the optimizer performs.
Setup
The model is a decoder-only GPT with RoPE, RMSNorm (pre norm), SwiGLU. All experiments share identical hyperparameters except the optimizer configuration. Total training is roughly 5.7B tokens on FineWeb Edu. Evaluation uses validation loss and HellaSwag accuracy. Single NVIDIA B200 with torch.compile().
Model
Training
Muon in Brief
For a full treatment, see Keller Jordan’s original writeup and Jeremy Bernstein’s derivation. The short version:
Muon replaces the usual gradient update with an orthogonalized one. It accumulates gradients into a momentum buffer, then projects that buffer onto the nearest orthogonal matrix before applying it to the weights. Concretely, for a matrix , the update becomes . Every singular value is set to 1, so no single gradient direction dominates.
This projection is computed efficiently via Newton-Schulz with 5 iterations, usually running in bfloat16. The FLOP overhead is about 1% for typical batch sizes.
Because orthogonalization only works on 2D matrices, Muon is paired with AdamW in a dual optimizer setup. Muon handles attention projections and MLP weights. AdamW handles embeddings, norms, the output head, and biases (if you still use them).
Why Splitting Projections Matters
In most transformer implementations, Q, K, and V are fused into a single (n_embd, 3·n_embd) linear layer. This doesn’t matter for AdamW as it treats each weight as an independent object. Muon sees a matrix as one object, which means the updates for Q, K, and V are all orthogonalized as one.
Queries, keys, and values serve different roles. There is no reason their gradient updates should be forced into the same directions (which is roughly what Muon does).
The same logic applies to the SwiGLU MLP, where the gate and up projections are typically fused into one (n_embd, 2·hidden_dim) matrix. The gate controls flow (via SiLU), while the up projection carries content. Muon’s whole-matrix orthogonalization does not see that boundary either.
Splitting these into separate linear layers lets each projection receive its own independent orthogonal update at the cost of a minor slowdown in token throughput. This observation was first made empirically for QKV by Vlado Boza in the context of NanoGPT speedrunning. My experiments evaluate how much it really matters and extend it to SwiGLU.
Results
Phase 1: AdamW VS Muon
For the initial setup, using torch.optim.Muon with adjust_lr_fn="match_rms_adamw" (Moonshot AI’s implementation) proved highly effective right out of the gate. This automatically calibrates the Muon LR relative to AdamW’s RMS update size, removing the need for manual LR scale tuning. It outperformed AdamW on both val loss and HellaSwag.
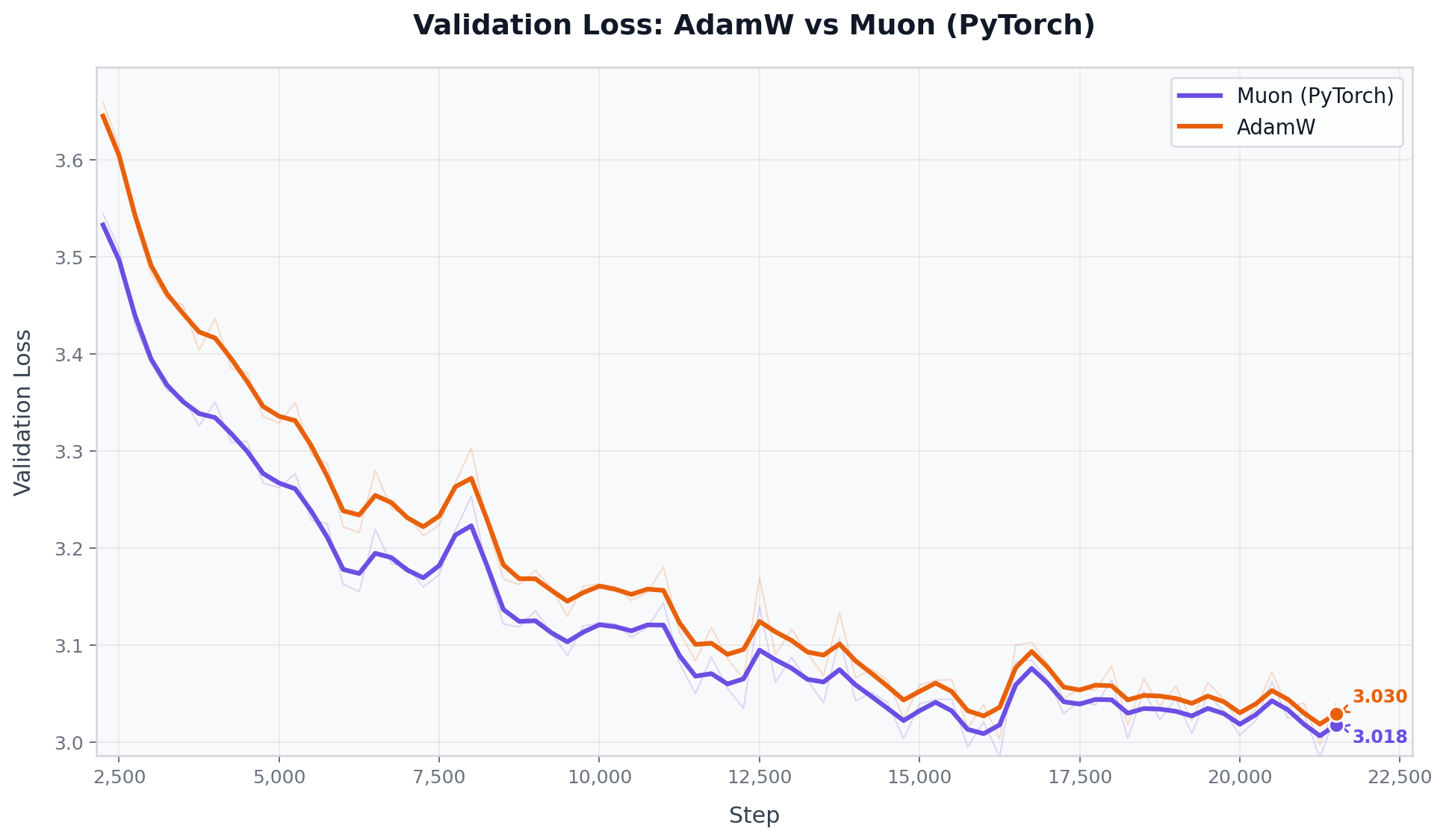
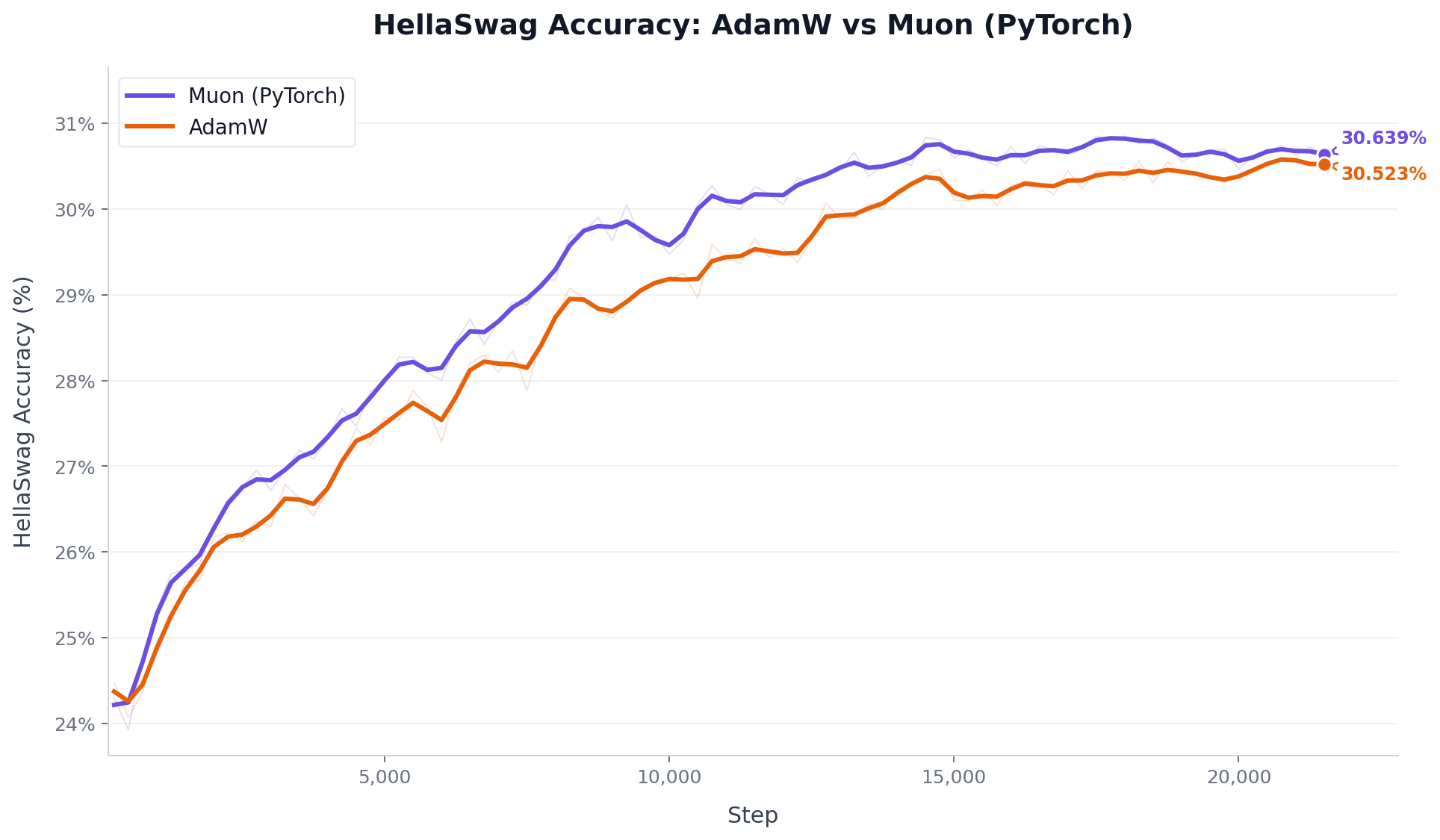
Phase 2: Projection Splitting
With PyTorch Muon as the optimizer, I tested three split configurations: Split QKV, Split MLP (SwiGLU), and Split Both. is relative to the AdamW baseline.
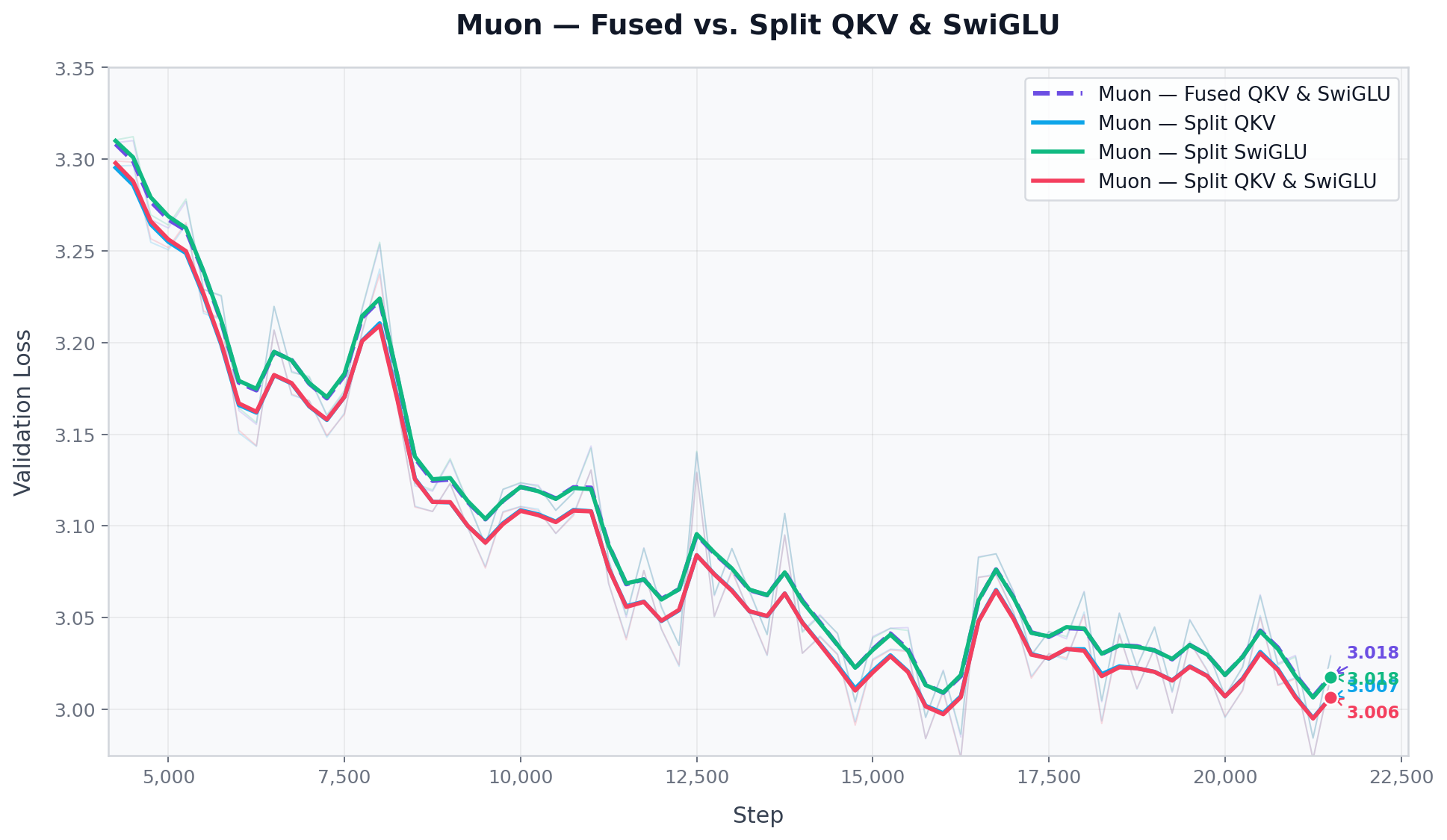
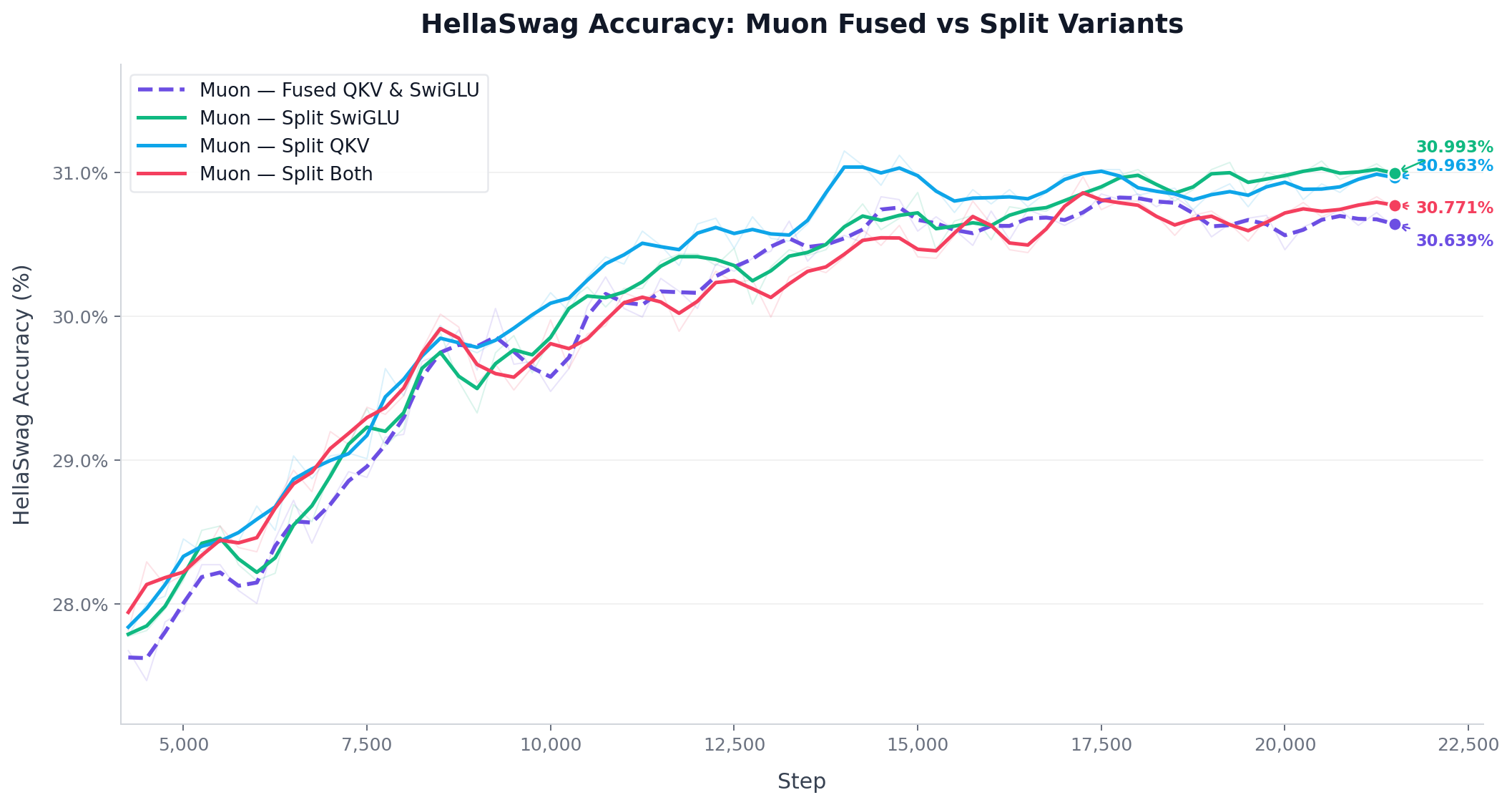
Splitting QKV consistently improved results. Splitting the MLP gate and up projections had no measurable effect. The model with split QKV + fused MLP matched the model with everything split.
Throughput Impact of Splitting Projections
Splitting the linear layers allows the Muon optimizer to orthogonalize projections independently, but how does this impact training speed?
As expected, standard AdamW provides the fastest throughput. Running the default fused PyTorch Muon implementation introduces a minor ~2.1% slowdown due to the overhead of the Newton Schulz orthogonalization.
But to my surprise, splitting the projections did not slow it down further. It actually improves the throughput slightly compared to the fused Muon baseline. The fastest setup was having both split, which cut the slowdown penalty in half to just ~1.1%.
My hypothesis is that the individual shapes of Q, K, and V are more GPU-friendly when split. Matrices with dimensions that are multiples of a power of 2 tend to fit more cleanly onto the kernel grid and allow more threads to run in parallel. Fused QKV produces a (1024, 3072) matrix; split, each projection becomes a clean (1024, 1024).
Conclusions
Split attention projections when using Muon. Fused QKV forces a joint orthogonal constraint across Q, K, and V. Splitting costs nothing and consistently helps.
MLP splitting does not matter at the hundred million scale. The gate and up projections in SwiGLU did not benefit from being split at 280M parameters. This may change at larger scale where the fused matrix becomes more rectangular. Worth revisiting.
What’s Next
Part II will add Mixture of Experts. At hundreds of billions of parameters MoE is a clear win, but at 240M active parameters it is an open question whether routing overhead and load balancing buy you anything over a dense model on the same compute budget. Each expert is also a smaller, more square matrix. This should be a better fit for Muon’s orthogonalization.
Repository: https://github.com/k-luka/GPT